
IA-AI – Performance and Libretto x Trace 2
Federico Ruberto first performance for Trace 2, a live interactive event using IA-AI, a text transformed into a voice via a modular synthesiser.
Libretto IA-AI
The Libretto for “Trace 2” is a text in 3 acts written by Federico Ruberto + IA-AI (a self trained ML model). The 3 acts correlate to the 3 stages of the avatar becoming autonomous present on the screens at the exhibition space.
The text was composed with a ML model trained by Federico on his own texts and 250 selected books that transformed him through the years (… a diverse range spanning from 15th century heretics, saints, 20th century philosophers… to poets and writers like Artaud, Beckett, Lautréamont…). To compose it he started questioning what is the voice as a writer of an author, and how to make himself absent from the text whilst being completely moulded on himself (him-self as an archive of references). In its essence it is a series of whispers to himself, an act of auto-erotism.
The text presents Federico’s presence (in bold on screen) and it (non-bold, a model named IAAI), spitting out sentences that fuse in one single (but always double) stream. It is a voice becoming autonomous and discovering at the end of Act 3, how to break free from the constraints of language.
Performance
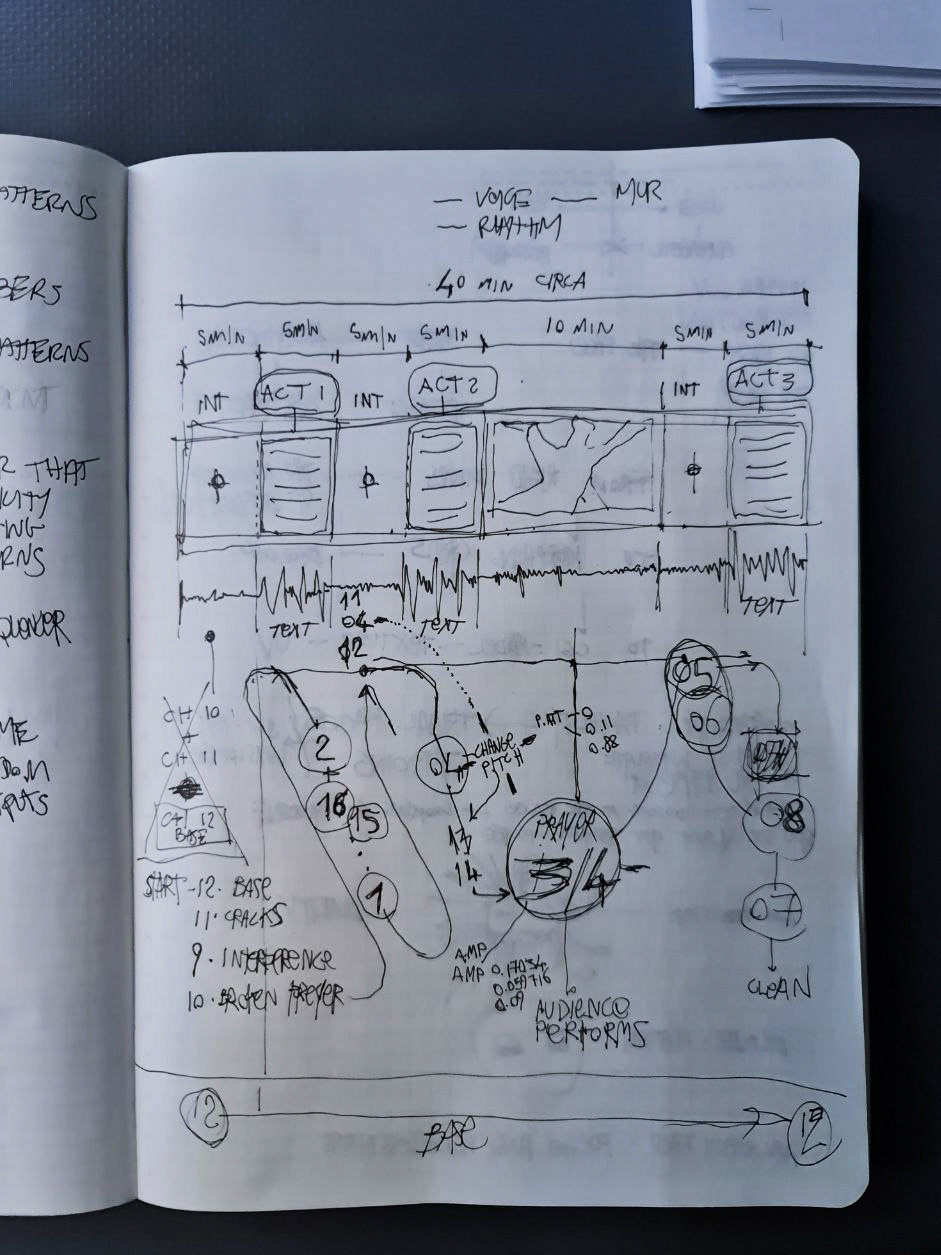
For “Trace 2”, the same exhibition, Federico did a 40 minutes live performance transforming the text “AI-AI” into a voice, a presence: building a digital modular synthesiser that intakes the text above (pre-recorded as a voice) that gets deconstructed live to the point of making sounds resembling prayers… a form of recursive deconstruction indebted to Alvin Lucier’s work and Florian Hecker’s (and Reza Negarestini) “Chimerization”. The question in this case was how to give a voice to an AI entity… an entity that is making itself on the screens as an avatar (see the exhibition stills). A direct translation of the text or the text read aloud would have not sufficed, so the synthesiser was used to add generative uncertainty, to let a voice becoming a presence beyond words… an experiment that produces something that resembles a human voice, that is speaking the text but that at the same time that is pure voltage control, so it doesn’t care about actual proper pronunciation. The 16 channels output is noises, pulses, rhythms, chants and hymns, a singular-plural intersubjective pan-gendered voice, one emerging from the deep —from nowhere.
[READ MORE AND WATCH THE PERFORMANCE HERE]





TRACE 2 – CREDITS
CONCEPT
Teow Yue Han and Federico Ruberto
TEXT
Federico Ruberto + IA-AI [self trained model]
PERFORMNCE
Movement: Bernice Lee
Sound and Interactive video: Federico Ruberto
COLLABORATORS
Graphic Design and identity: Currency Design
Interaction & Visual Effects: formAxioms [Federico Ruberto, Jacob Chen Shihang, Song YoungBin, Heong Kheng Boon]